


II. Introduction, dĂŠmarche et diagnostic▲
II-A. Introduction - quelques rĂŠflexions pour bien dĂŠmarrerâŚ▲
- Ne recevoir aucune chose pour vraie tant que son esprit ne l'aura clairement et distinctement assimilĂŠ e prĂŠalablement.
- Trier ses difficultĂŠs afin de mieux les examiner et les rĂŠsoudre.
- Ătablir un ordre de pensĂŠes, en commençant par les plus simples jusqu'aux plus complexes et diverses, et ainsi de les retenir toutes et en ordre.
- Passer toutes les choses en revue afin de ne rien omettre.
Descartes, discours de la mĂŠthode.
Toutes ces Êtapes sont rigoureusement les mêmes lors de la mise en place d'un plan d'amÊlioration des performances :
1. ne pas appliquer de solutions prÊconçues : vous risquez de perdre du temps à mettre en place une solution qui ne rÊsout pas votre problème. La première Êtape est de reproduire les conditions dans lesquelles les performances se dÊgradent et d'identifier de manière certaine le problème.
2. commencer dans l'ordre : gÊnÊralement il y a un problème dominant. Il ne sert à rien de rÊsoudre les points secondaires avant le premier. Les performances sont souvent amÊliorÊes par les actions les plus simples. Par exemple, s'il y a un problème sur l'accès aux donnÊes, on peut obtenir un facteur 100 en travaillant sur les index de la base de donnÊes tandis que changer les serveurs permettrait d'obtenir un facteur 4.
3. mettre en place les solutions jusqu'au bout : dans la plupart des cas, il ne se pose pas un, mais plusieurs problèmes de performance. Vous devez les identifier et les rÊsoudre un par un. Vous vous rendrez certainement compte que trouver une première solution n'est que le dÊbut de la dÊmarche. L'Êcueil dans ce cas-là est de croire que ce n'Êtait pas la bonne solution et de l'abandonner pour en chercher une autre plus  universelle . C'est une erreur. Les performances s'amÊliorent en accumulant les solutions.
4. procÊder de manière itÊrative : les performances vont s'amÊliorer après ces premières actions, mais cela ne suffira peut-être pas. Il est important de mesurer le progrès et d'itÊrer.
II-B. Vue d'ensemble de la dĂŠmarche▲
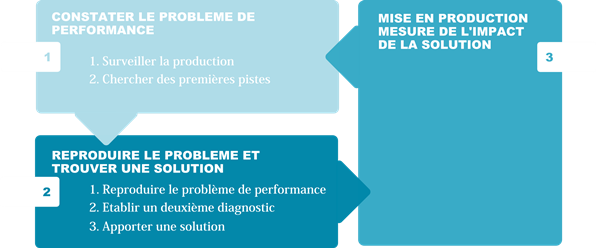
II-B-1. Constater le problème de performance▲
Cette Êtape consiste à chercher les premières pistes d'optimisation. Elle est conduite à l'aide des outils de surveillance de la production. L'objectif est de trouver une orientation à la recherche de solutions dans un des quatre domaines suivants :
- applicatif (Apache - PHP)Â ;
- base de donnÊes ;
- rÊseau ;
- infrastructure matĂŠrielle.
NOTE : dans les premières itÊrations de la dÊmarche, certaines solutions sont Êvidentes. Dans le cas d'un problème sur une page ou une fonctionnalitÊ prÊcise, il est souvent simple d'identifier rapidement d'oÚ vient le problème. Aussi, si la solution est Êvidente, il suffit de proposer une correction et de passer directement à l'Êtape 3.
II-B-2. Reproduire le problème et trouver une solution▲
La deuxième Êtape consiste à reproduire les conditions dans lesquelles les performances se dÊgradent. Cela permettra de travailler beaucoup plus rapidement sur le problème, et parfois même sans solliciter l'environnement de production.
Une fois que les conditions dans lesquelles les performances ne sont pas bonnes sont identifiĂŠes, il convient de mettre en Ĺuvre et de tester les diffĂŠrentes solutions.
II-B-3. Mise en production et mesure de l'impact▲
Deux ÊlÊments perturbent la mesure exacte de l'optimisation apportÊe :
- les diffÊrences entre les environnements : pour des raisons Êconomiques, il est rare d'avoir un environnement de prÊproduction parfaitement identique à celui de production ;
- les conditions dans lesquelles les performances se dÊgradent : il est parfois impossible ou trop coÝteux de reproduire ces conditions. Par exemple, si les performances se dÊgradent lors d'un pic d'audience, reproduire l'accès au service de nombreux utilisateurs simultanÊment peut être complexe.
Aussi, dans bien des cas, la seule mesure valable est faite sur l'environnement de production. C'est pour cela que mettre en place une dĂŠmarche prĂŠalable a beaucoup d'importance. Elle permet de rĂŠduire le risque et de rĂŠduire le temps nĂŠcessaire Ă la mise en place des dispositifs d'optimisation.
II-C. Ătablir les premières pistes d'optimisation▲
II-C-1. Ressources touchĂŠes▲
Un projet est un assemblage de plusieurs ressources matĂŠrielles et logicielles. Aussi, soumise Ă une forte charge, une de ces ressources est susceptible de limiter la performance de l'ensemble. Les outils de surveillance des infrastructures de production permettent de dĂŠterminer quelle ressource est liĂŠe Ă la dĂŠgradation des performances.
Parmi les ressources matÊrielles, il y a :
- CPUÂ ;
- RAMÂ ;
- bande passante ;
- disques durs.
Parmi les ressources logicielles, on peut citer :
- nombre de fichiers ouverts ;
- nombre de cĹurs utilisĂŠs ;
- nombre de connexions Ă la base de donnĂŠes.
Afin d'Êtablir des pistes de solutions à Êtudier, il convient de mesurer l'utilisation des diffÊrentes ressources citÊes ci-dessus afin de dÊterminer quelles sont celles qui sont exploitÊes de manière trop intense.
Ces mesures servent aussi Ă comprendre sous quelles conditions et Ă quels moments les performances sont moins bonnes. De nombreux outils permettent d'effectuer ces mesures. Ils sont dĂŠcrits dans les paragraphes suivants.
NOTE : il ne faut pas croire que la libÊration de la ressource la plus sollicitÊe permet nÊcessairement d'amÊliorer de manière spectaculaire la performance de l'ensemble. Bien souvent, produire une première optimisation va conduire à trouver qu'une autre ressource est saturÊe à son tour. C'est pourquoi la dÊmarche est itÊrative.
Dans cette dĂŠmarche il faut respecter un certain ordre. Les ressources matĂŠrielles doivent systĂŠmatiquement ĂŞtre analysĂŠes avant les ressources logicielles (mais cela ne signifie pas que les solutions sont nĂŠcessairement matĂŠrielles). Par exemple, il faut s'assurer que l'utilisation du CPU par la base de donnĂŠes n'est pas critique avant de se pencher sur la configuration du nombre de connexions Ă la base de donnĂŠes.
BON à SAVOIR : le disque dur doit être analysÊ après la RAM en raison du phÊnomène de SWAP qui fait porter l'excÊdent de mÊmoire utilisÊe par le disque dur lorsque la RAM disponible est insuffisante.
II-C-2. Ătablir les premières pistes d'optimisation - les outils serveur▲
Si vous savez à quel moment prÊcis se produisent les problèmes de performance, vous pouvez alors utiliser des outils de mesure  temps-rÊel . Ces outils sont pour la plupart utilisÊs en ligne de commande sous Linux.
II-C-2-a. Top▲
La commande TOP est l'outil de monitoring des systèmes Linux par excellence. TOP produit une liste des processus actifs du serveur, et dÊtaille leur consommation de temps processeur (CPU) et de mÊmoire (RAM). Il indique Êgalement la charge moyenne du système sur trois pÊriodes : 1 minute, 5 minutes et 15 minutes. Si cet outil ne permet pas de connaÎtre directement l'origine du problème, ce chiffre aide à confirmer s'il s'agit d'un pic d'activitÊ ou bien si la machine est saturÊe depuis un certain temps.
NOTE : il est à noter que TOP a ÊtÊ pensÊ de manière à ne pas faire partie lui-même des processus le plus consommateurs de ressources qu'il mesure.
BON à SAVOIR : TOP est un outil extrêmement utile. Il permet d'identifier les problèmes les plus Êvidents sur la consommation de RAM et de CPU. En revanche, il est possible que TOP ne dÊtecte aucun problème apparent, alors que votre machine est belle et bien ralentie. Cela se produit notamment si le problème se situe au niveau des accès disque, ou encore au niveau des ressources logicielles.
II-C-2-b. IOstat▲
La commande IOSTAT est utilisĂŠe pour contrĂ´ler la charge des pĂŠriphĂŠriques entrĂŠe/sortie en observant leur temps d'activitĂŠ par rapport Ă leur taux de transfert. Cette commande est souvent utile pour harmoniser la charge lecture/ĂŠcriture entre les diffĂŠrents disques durs.
II-C-2-c. IOtop▲
Si l'accès en lecture/Êcriture de votre disque est saturÊ (par exemple trop de requêtes INSERT, UPDATE ou DELETE peuvent surcharger votre disque en Êcriture), la commande TOP peut s'avÊrer insuffisante comme exposÊ ci-dessus. IOTOP prÊsente, de la même manière que TOP, les processus qui consomment le plus de lecture et d'Êcriture sur votre système.
II-C-2-d. Dstat▲
DSTAT est un outil de mesure transversal. Alors que TOP se spÊcialise dans l'activitÊ CPU et IOTOP dans les accès disques, DSTAT permet de surveiller l'activitÊ sur le serveur de manière transverse. L'utilisateur peut dÊcider d'afficher des indicateurs tels que l'activitÊ CPU, l'activitÊ des disques, l'activitÊ rÊseau, etc. côte à côte.
NOTE : ce n'est pas l'outil le plus prÊcis, mais il est très pratique pour comparer rapidement diffÊrentes mesures du système. De plus, il permet aisÊment de rÊaliser des logs analysables sur un tableur comme Excel ou Open Office Calc.
II-C-3. Ătablir les premières pistes d'optimisation - les outils client▲
II-C-3-a. Webpagetest.org▲
Webpagetest.org est un site Internet permettant de faire un audit du chargement d'une page web. On retrouve le diagramme chronologique des ĂŠlĂŠments tĂŠlĂŠchargĂŠs, la check-list des points courants Ă optimiser, un rendu de la page avec une image au bout de quelques secondes et des graphiques rĂŠsumant les ĂŠlĂŠments rĂŠcupĂŠrĂŠs.
II-C-3-b. Firebug▲
Firebug est un plugin de Firefox apprĂŠciĂŠ des dĂŠveloppeurs web. Il permet d'inspecter le code HTML en ciblant directement l'ĂŠlĂŠment dans la page, d'ĂŠditer le style CSS pour tester le rĂŠsultat directement, dĂŠboguer le JavaScript avec des points d'arrĂŞts et un mode pas Ă pas et espionner le trafic XMLHttpRequest (Ajax). Tout comme webpagetest.org, Firebug permet de disposer d'un diagramme chronologique du chargement de la page. Firebug ĂŠtant un outil local, vous pouvez mĂŞme l'utiliser pour tester votre application en phase de dĂŠveloppement.
II-C-3-c. YSlow et Page Speed▲
YSlow et Page Speed sont des extensions de Firebug, respectivement dĂŠveloppĂŠ par Yahoo et Google, permettant d'analyser les performances du trafic rĂŠseau de la page. Ces extensions analysent le code de votre page web et proposent de nombreux conseils d'optimisation de votre code HTML et de votre serveur web (utilisation du cache HTTP, etc.),
BON à SAVOIR : webpagetest.org et YSlow fournissent à peu près les mêmes ÊlÊments à une nuance près. webpagetest.org permet de localiser (physiquement) d'oÚ Êmane la demande. En fonction de ce lieu, les diagrammes chronologiques peuvent varier.
II-C-4. Les outils de monitoring▲
Si vous ne pouvez pas prÊvoir l'occurrence des problèmes de performance, il sera plus simple de se servir d'outils de monitoring afin de pouvoir accÊder à l'historique des mesures de vos ressources.
II-C-4-a. Munin▲
Munin permet de surveiller les diffĂŠrentes ressources de vos serveurs. Un client est installĂŠ sur chacune des machines, et les donnĂŠes mesurĂŠes sont agrĂŠgĂŠes Ă intervalle rĂŠgulier vers une machine centrale (oĂš le serveur Munin se trouve), et prĂŠsentĂŠes sous forme graphique.
Munin permet, dans son installation la plus simple, de surveiller l'utilisation du disque, de la RAM, du CPU et du rÊseau. Cet outil est Open Source et il existe de nombreux plugins permettant de mesurer d'autres ressources, telles que :
- les temps de rĂŠponse (HTTP response time)Â ;
- la consommation CPU pour une sĂŠlection de processus (multimemory plugin)Â ;
- taux d'utilisation des connexions MYSQL (mysql_connections)âŚ
BON à SAVOIR : la granularitÊ minimale de Munin (intervalle de temps entre deux mesures) est de 5 minutes. Si vous faites face à des problèmes de performance lors de pics de charge très courts (de 5 à 15 minutes), Munin peut s'avÊrer insuffisant pour vous apporter des informations suffisamment dÊtaillÊes.
II-C-4-b. Nagios▲
Nagios est un outil de surveillance de serveurs. Contrairement à Munin, Nagios n'est pas un outil de mesure de l'activitÊ. Il est utilisÊ uniquement pour remonter des alertes. Extensible avec des plugins, il peut remonter des alertes comme :
- activitÊ CPU trop importante ;
- indisponibilitÊ du serveur web ;
- RAM insuffisante ;
- temps de rĂŠponse dĂŠgradĂŠsâŚ
Lorsqu'une alerte est remontĂŠe, l'outil peut ĂŞtre paramĂŠtrĂŠ pour prendre des actions, comme envoyer un mail d'alerte aux administrateurs, ou encore envoyer des SMS.
NOTE : si les problèmes de performance se produisent de manière alÊatoire et non reproductible, Nagios peut être utilisÊ pour vous alerter des problèmes rencontrÊs. Vous pourrez alors vous connecter au serveur pour effectuer des mesures plus approfondies en temps rÊel.
II-C-4-c. Autres outils▲
D'autres outils vous permettent de connaĂŽtre l'activitĂŠ de votre infrastructure. Par exemple, un outil de web analytics permet de connaĂŽtre approximativement le nombre de visiteurs sur votre plateforme.
D'autres outils (ĂŠmergents) vous permettent d'avoir une vision encore plus prĂŠcise de votre activitĂŠ. Par exemple Collectd (http://collectd.org) permet de descendre sous la barre des 5 minutes imposĂŠe par Munin.
II-C-5. Ătablir les premières pistes en fonction des ressources▲
II-C-5-a. CPU / RAM▲
Si la piste s'oriente vers une activitÊ critique de la RAM ou du CPU, c'est probablement parce que la commande  TOP  aura indiquÊ que les processus apache (PHP) ou mysqld (BDD MySQL) consomment une quantitÊ trop importante de ces ressources. Selon le processus concernÊ, il faudra alors identifier plus prÊcisÊment la ou les causes de cette activitÊ trop importante :
Apache/PHP : si votre problème se pose sur une page en particulier (sauf la page d'accueil oÚ les problèmes sont souvent liÊs au nombre de connexions simultanÊes), il est utile d'analyser le code exÊcutÊ par celle-ci pour dÊceler un potentiel dÊfaut. Si, au contraire, il s'agit de l'ensemble de l'application, c'est certainement dÝ à un trop grand nombre d'utilisateurs. Il est alors intÊressant de mettre en place des mises en cache (côtÊ serveur et côtÊ client) ou des traitements asynchrones afin de limiter l'engorgement lors d'un afflux trop important.
MySQL : une très grande partie des problèmes de performance liÊs à la base de donnÊes peut être rÊsolue en utilisant les index adÊquats ou en mutualisant les requêtes. Avant cela, il faut systÊmatiquement Êtablir une liste dÊtaillant à la fois la frÊquence de la requête (ou du type de requête) et le coÝt de cette requête.
Autre processus : vous pourriez constater via  top  qu'un autre processus de votre serveur occupe la totalitÊ de votre temps processeur. Il est alors important d'identifier le coupable. Si vous avez installÊ d'autres services sur votre serveur, l'un d'entre eux pourrait être le coupable. Par exemple, un problème sur un serveur de mail ou une base de donnÊes full-text, etc., pourrait dÊclencher cette consommation CPU qui ralentirait votre serveur.
Si vous ne connaissez pas le nom du processus, n'hÊsitez pas à vous aider d'une recherche sur Google pour en apprendre plus. Et si vous êtes persuadÊs de n'avoir jamais installÊ le processus incriminÊ, investiguez ! Votre serveur a peut-être ÊtÊ piratÊ. C'est certainement le cas si vous laissez un accès SSH disponible depuis Internet avec des mots de passe trop simples. N'oubliez pas qu'un hacker n'a pas besoin des accès  root  pour installer et exÊcuter ses programmes. Un simple accès utilisateur suffit. Il peut alors transformer votre machine en serveur de fichiers ou bot, et les processus que vous voyez dans  top  sont à coup sÝr nÊfastes. Tirez à vue !
II-C-5-b. Bande passante▲
Pour obtenir une première piste d'optimisation, vous devez rechercher le ou les ÊlÊments qui consomment de la bande passante. Par exemple, une page qui renvoie une vidÊo de 100 Mo peut dÊgrader les performances de votre site web si elle est appelÊe de nombreuses fois.
Apache : la première piste à examiner est les logs Apache afin d'observer combien consomme chaque requête et rechercher quels sont les pages ou les fichiers volumineux. En effet, les logs Apache sont assez flexibles et il est possible de les configurer pour afficher la quantitÊ de donnÊes envoyÊes à chaque requête.
NOTEÂ : lorsqu'on mesure la bande passante du serveur, il est important de garder Ă l'esprit que le serveur n'est pas le seul Ă saturer. Votre connexion Internet ADSL saturera certainement avant. Si IOStat ne montre pas de surconsommation rĂŠseau, la raison d'un affichage lent pourrait ĂŞtre votre connexion Internet, ou n'importe quel ĂŠlĂŠment rĂŠseau entre votre client et votre serveur.
II-C-5-c. Disque dur▲
Vos consommations de RAM et de CPU semblent normales et votre bande passante n'est pas saturÊe. Il y a de grandes chances que votre disque dur soit le facteur limitant. à moins que votre application n'effectue un très grand nombre de lectures/Êcritures sur le disque (ouverture et modification de fichiers, crÊation de documents, etc.), il est probable que MySQL soit responsable. En effet, les requêtes MySQL SELECT peuvent provoquer des accès disque en lecture (si le rÊsultat de cette requête n'est pas en cache), et les autres types de requêtes (INSERT, UPDATE, DELETE) font systÊmatiquement des accès en Êcriture.
II-C-5-d. Aucun de ces points ne semble critique ?▲
Le système peut être  bridÊ  par ses ressources logicielles ou par des latences rÊseau.
Quelques pistes : nombre de threads MySQL, nombre de fichiers ouverts simultanÊment.
II-D. Reproduire le problème & ĂŠtablir le diagnostic▲
II-D-1. Reproduire les problèmes de performance▲
Reproduire les conditions dans lesquelles les performances se dÊgradent est de plus en plus difficile au fur et à mesure que l'on effectue des optimisations. Or, savoir si l'on fait le bon scÊnario de test est presque aussi important que de faire la bonne optimisation (celle qui nous permettra vraiment d'amÊliorer les performances sur l'environnement de production). L'objectif est donc de simuler le fonctionnement de votre site web sur un seul des aspects (base de donnÊes, accès disque, etc.).
II-D-1-a. ab▲
ab est un outil d'Êvaluation des performances de votre serveur web. Il indique le nombre de requêtes par seconde que votre application est capable de prendre en charge. Les deux paramètres principaux sont le nombre de requêtes simultanÊes ainsi que le nombre total de requêtes à effectuer.
BON à SAVOIR : bien qu'il soit possible d'utiliser d'autres paramètres pour passer des valeurs POST, des cookies, etc., cet outil n'est pas fait pour simuler efficacement l'activitÊ d'un ou plusieurs utilisateurs qui naviguent sur votre site, mais plutôt pour simuler l'arrivÊe massive d'utilisateurs sur une page. En effet, ab n'intègre pas de notion de scÊnario, car il ne peut tester qu'une seule URL à la fois.
II-D-1-b. JMeter▲
JMeter est une application que l'on peut dÊployer sur un poste de travail (il vaut mieux qu'il soit dÊdiÊ afin que le dÊveloppeur qui s'en sert puisse travailler pendant les runs de tests). C'est un outil qui permet de simuler un grand nombre de requêtes concurrentes HTTP et donc de simuler le comportement du site avec un grand nombre de visiteurs. L'outil produit une synthèse graphique des rÊsultats du test.
NOTEÂ : dans le cas d'une architecture LAMP, l'outil ne prĂŠsente d'intĂŠrĂŞt que pour les requĂŞtes HTTP. En revanche, il permet de tester beaucoup d'autres ĂŠlĂŠments annexes (serveurs de mails, connexion JDBC, etc.).
BON à SAVOIR : JMeter n'Êmule pas complètement un navigateur (contrairement à un outil comme Selenium). Il est donc plus difficile de crÊer un jeu de tests qui soit reprÊsentatif du comportement exact de l'application.
II-D-1-c. Selenium Grid (reproduction de scĂŠnario)▲
Selenium est une boite à outils permettant de rÊaliser des tests en simulant l'activitÊ d'un ou de plusieurs utilisateurs sur un site web. Grâce à un plugin Firefox, vous avez la possibilitÊ  d'enregistrer  un scÊnario en naviguant sur le site, puis de le rejouer à volontÊ, en vÊrifiant que l'affichage des pages est conforme aux attentes.
Selenium Grid vous permet de simuler une montÊe en charge de votre application en jouant plusieurs fois le même scÊnario en parallèle. Si vous disposez de suffisamment de ressources, il vous sera possible de reproduire les problèmes de performance.
II-D-1-d. Batchs de requĂŞtes SQL▲
Obtenir la liste de toutes les requĂŞtes faites Ă la base de donnĂŠes pendant l'exĂŠcution d'un scĂŠnario reprĂŠsentatif, puis le rejouer vous permettra de simuler l'impact de l'application sur la charge de votre serveur de donnĂŠes.
Pour faire cela, vous pouvez soit Êcrire dans un journal les requêtes au niveau de l'applicatif, soit configurer MySQL pour tracer toutes les requêtes (paramètre  log  de votre fichier my.ini ou my.cnf).
Vous avez la possibilitÊ de rejouer ce batch de façon unitaire pour mesurer le gain de performance grâce à vos optimisations, mais aussi de lancer plusieurs batchs en parallèle pour simuler un pic activitÊ.
II-D-2. Ătablir le diagnostic▲
Comme expliquÊ auparavant, la solution est parfois Êvidente, il n'est parfois pas nÊcessaire de pousser plus loin l'analyse de votre problème. En revanche, dans certains cas il faut prÊciser le diagnostic afin d'appliquer la correction appropriÊe.
Dans ce cas, il existe des outils et des dĂŠmarches simples permettant d'investiguer plus en profondeur sur l'utilisation des ressources.
II-D-2-a. Logs Apache▲
SYMPTĂMESÂ : votre site rĂŠpond correctement en temps normal, mais les temps de rĂŠponse se dĂŠgradent sous la charge.
Les logs Apache tracent toutes les requĂŞtes faites au serveur Apache. En les configurant correctement, vous aurez la possibilitĂŠ d'obtenir le temps de rĂŠponse de votre site. En utilisant des outils de parsing appropriĂŠs (AWStats, Visitors, ou WebLog Expert), vous pourrez facilement visualiser le comportement de votre site en fonction du nombre d'utilisateurs connectĂŠs.
II-D-2-b. Logs MySQL (dont slow queries)▲
SYMPTĂMESÂ : MySQL consomme ĂŠnormĂŠment de CPU ou le disque dur sature.
Les logs MySQL retracent l'activitĂŠ de votre serveur de donnĂŠes. Le journal de log simple (celui configurĂŠ par dĂŠfaut) pourra vous renseigner sur la stabilitĂŠ du serveur MySQL.
Le fichier de slow queries (il est parfois nĂŠcessaire de configurer ce log) liste l'ensemble des requĂŞtes dont la durĂŠe d'exĂŠcution est supĂŠrieure Ă un seuil donnĂŠ (lui aussi configurable).
Les requĂŞtes contenues dans ce fichier seront donc celles qui mobilisent le plus le serveur, et donc souvent celles qui devront ĂŞtre optimisĂŠes.
Exemple de configuration du log slow queries (dans le fichier de configuration MySQL):
[mysqld]port=3306log_slow_queries= 1long_query_time= [seuil]log-slow-queries= [chemin vers le fichier de log]II-D-2-c. Analyse/parsing de code - Xdebug▲
SYMPTĂMESÂ : PHP consomme ĂŠnormĂŠment de CPU.
La fonction Profiler de Xdebug est un outil qui permet d'analyser les temps d'exĂŠcution de votre code PHP. Il permet de savoir combien de temps est passĂŠ dans chacune des fonctions du code, et donc de dĂŠterminer quelle partie de code est moins performante.
II-D-2-d. MySQLTuner▲
MySQLTuner est un script Êcrit en Perl qui vous permet d'Êprouver une installation MySQL rapidement et de faire des recommandations pour amÊliorer les performances et la stabilitÊ de la base de donnÊes. Il produit un rapport dÊtaillant :
- les possibilitÊs offertes par la configuration en cours ;
- des mĂŠtriques telles que le nombre de jointures effectuĂŠes sans index, hit ratio du cacheâŚÂ ;
- des recommandations à la fois sur la manière d'exÊcuter les requêtes, et sur les paramètres de configuration à modifier.
II-D-3. Audit de la structure de la BDD▲
La structure de la base de donnÊes influence fortement ses performances. Ainsi, il faut s'assurer que vos tables contiennent les index appropriÊs, que les clÊs Êtrangères sont en place.
VÊrifiez aussi que les triggers Êventuels ne nuisent pas aux performances : si chaque insert dans une table implique l'exÊcution d'un script complexe, il vaudra mieux mettre en place des batchs SQL asynchrones (quand c'est possible bien sÝr).
BON à SAVOIR : si les bonnes pratiques en matière de structure relationnelle des bases de donnÊes recommandent le respect des normes (on parle de base de donnÊes normÊe), la complexitÊ de relation entre les diffÊrentes tables peut nuire aux performances. Il faut toujours partir d'une base normalisÊe, celle-ci Êtant bien plus facile à maintenir. En cas de problème de performance, on effectuera une dÊnormalisation au cas par cas.
II-D-3-a. RĂŠseau interne/rĂŠseau externe▲
Si vous avez sĂŠparĂŠ votre serveur applicatif et votre base de donnĂŠes, assurez-vous au prĂŠalable que votre bande passante n'est pas consommĂŠe principalement en interne. En effet, si vous effectuez une grande quantitĂŠ de requĂŞtes ou des requĂŞtes avec des rĂŠsultats de taille importante, il est possible que ce soit la raison de la baisse des performances en cas de forte affluence.
De manière gĂŠnĂŠrale, vous devez veiller Ă envoyer le moins de donnĂŠes possible du serveur de base de donnĂŠes vers l'application. Ăcrivez les requĂŞtes les plus sĂŠlectives possible et faites le maximum d'agrĂŠgations dans vos requĂŞtes SQL.